
A programmers Mindset
A programmer’s mindset is always towards solving the problem logically. They consider data is all sanitized before starting the programming process. For example, as soon as the look at the problem statement, if it is a python programmer, in their mind something like pandas dataframes, series, matplotlib’s pyplot or seaborn etc. form a picture. This mental picture takes precedence and urges the inner programmer to go after the problem head-on instantly. This fallacy is the most detrimental factor in turning programmers into data scientists. Here take a look at the way one of the programmer approached the given problem…
While there is no issue with the code per se, this approach might not be as effective if there are issues with the data presented and data needs to be sanitized or transformed. The problem was approached head on.
Data Scientist’s Mindset

I have come to realize, by my own experiences, the data scientist’s mental makeup and their way of thinking. Following are thoughts that take precedence over programming constructs for a data scientist:

- Do we have the requisite data if so, do I understand it? Do I have the requisite domain knowledge on this? Can I just look at data and draw inferences if I do not have the requisite domain knowledge? Is domain knowledge important for Exploratory Data Analysis, if so, what amount of knowledge is required? Is it a case that just basic knowledge would do or do I need to have a deep understanding of the concepts?
- Look at the data, form a basic understanding of the data domain.
- Check the data for being good:
- Is data cleansing needed
- What is the structure of data I am dealing with?
- What kind of data types are present in the data presented?
- Is it consumable by my programs or do I need transformations?
- Get a gist of the data, a sample set of data.
- Missing values – how do I treat the missing values, are there general guidelines in dealing with missing data in the specific domain, any specific instructions from the data provider on this front?
- How does data represent the missing values?
- Total null values, get these into a separate dataset to analyze them in detail.
- What part of data is continuous, what parts are categorical (read this as, what parts are numerical and what parts are non-numerical?
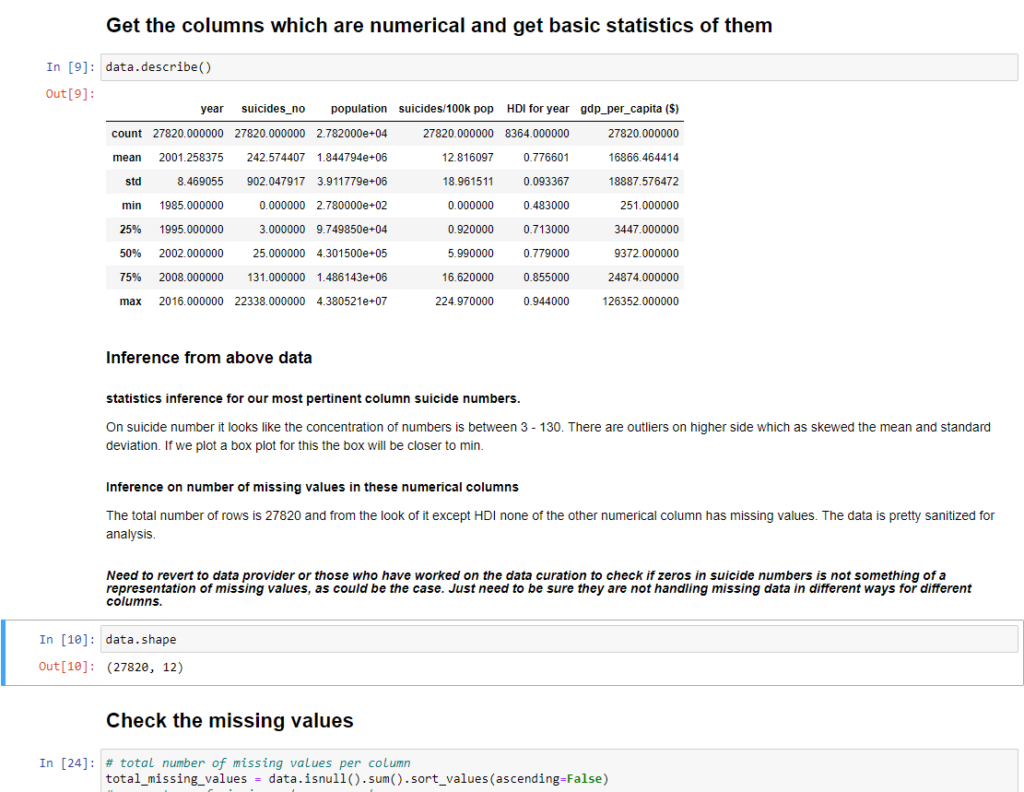
- Get a brief of general statistics on numerical data, for example, its distribution, its max and min, its mean, median, skewness etc.
- Create frequency tables of all the information that is most pertinent to the problem asked to be analyzed and are needed to explain the analysis.
Once you have done this exercise, you would be able to form a general idea on what you are dealing with and what could be the appropriate approach. Now turn-on the programmer in you and you would be better able to write logic needed, you are not blindly approaching, you have the necessary info-arsenal with you to take-on the beast. Once you are attuned to this way of thought process, even while selecting charts and tools for visualization would become simpler process and more effective for drawing inferences.
This was from my experience, in tackling the complex data of genomics at my work. Hope, these general guidelines might help future aspirants to succeed and be better equipped in their journey as a Data Scientist.